|
|
Practical project 2024 - Getting Started
(due 11:59pm Fri 17th May - end of week 11)
See also:
the Project
and
Clarifications (12/5)
There are two significant, and different,
networking aspects to be addressed in this project.
Once those aspects are designed, implemented, and tested,
attention can move to designing, implementing, and testing
the business logic of the project.
- Each station server needs to support queries from a web-browser,
that is both receive and respond to queries,
using the TCP/IP transport protocol.
When using TCP, a long-term connection is established between two processes
(between your web-browser and any of your "identical" station servers),
until either end-point closes the connection (and if either of them crashes,
the connection will be closed, but the other end may not know why).
The project requires that you use the
Hypertext Transport Protocol (HTTP)
and Hypertext Meta-Language (HTML) protocols
within a Transmission Control Protocol (TCP) over
Internet Protocol (IP)
connection for communication between the web-browser and each station server.
Very simple HTTP exchanges and simple HTML content are sufficient.
Your HTML content (text)
is embedded within the payload of HTTP,
which is embedded within the payload of TCP,
which is embedded within the payload of IP,
which is embedded within the payload of a Physical Layer frame (such as Ethernet).
Network traffic across a TCP/IP connection is bi-directional and reliable -
one end writes a query,
the other end reads the (uncorrupted) arriving query,
determines/calculates a response,
writes that response,
and the other (original) end reads it.
Both ends can write data at the same time -
the two messages do not interfere with each other when 'crossing'.
- Each station server also communicates with
other station servers using the UDP/IP datagram-based protocol.
While no long-lasting connection is established between
two communicating partners using UDP/IP,
they can communicate by writing and reading self-contained messages.
Each message (the payload of a datagram)
will arrive at only the intended destination zero or more times.
If a datagram arrives, it will be uncorrupted.
Each datagram is individually addressed,
so the same message (payload) can be sent to multiple destinations
in separate datagrams by (effectively) just changing the destination address.
Communication between web-browser and a station server
Let's see what a web-browser (acting as a client) sends to a server,
sending its traffic using HTTP.
Firstly, we'll need to know, or choose,
a port-number for the communication.
A port number is a small integer (on a server/computer)
identifying a 'communication endpoint' able to receive
some network communication from another computer.
Both the sending and receiving processes may be on the same computer,
and the operating system kernel (internally) uses the port-number to determine
if there's a running process able/wanting to receive the communication and,
if so, the kernel delivers the communication to that process.
OK, let's find an available port-number - meaning, one not currently in use
by another process.
Download this Linux/macOS bash shellscript
portsinuse.sh
(which will probably download when you click on the link),
make it executable, and run it:
shell> chmod +x portsinuse.sh
shell> ./portsinuse.sh
Choose a port-number not listed there (and above 1023),
say 4444,
and run the command:
shell> nc -l 4444
You've just started a new server process,
listening on port 4444,
and expecting a connection and network traffic using TCP/IP (the default).
Ahh, this project looks easy!
Now let's use your web-browser,
acting as a TCP/IP-based client,
to connect to that nc server.
Because (assuming) your web-browser and the nc process are running on
the same computer,
each will be able to communicate using the 'generic' hostname of localhost
(or, depending on your computer's configuration,
you may need to use the IP address 127.0.0.1).
Open a new tab in your browser,
and in the address bar enter the URL
http://localhost:4444/
In the shell window of your nc process you should immediately see what the browser has sent to nc,
commencing with:
GET / HTTP/1.1
Host: localhost:4444
.....
The 8 or so lines you see is a basic HTTP header (version 1.1),
followed by a blank line.
Your web-browser is still waiting for a reply from nc,
so we need to also reply using HTTP.
Type (cut-and-paste) in your shell window:
HTTP/1.1 200 OK
Content-Type: text/html
Connection: Closed
<html>
<body>
<h1>Hello from nc!</h1>
</body>
</html>
and then control-C or control-D to terminate the
TCP/IP connection between nc and web-browser.
You've replied with an HTTP header (version 1.1),
indicating that the 'request' was valid and understood (reply code 200),
indicated that the type of your reply will be HTML (case is insigificant),
and eventually sent 5 lines of HTML.
You should see the reply rendered in your browser's tab.
Now, repeat the whole exercise,
re-running nc and this time requesting the URL
http://localhost:4444/?to=Perth_Stn
into your browser.
You should see this new request arrive with:
GET /?to=Perth_Stn HTTP/1.1
Host: localhost:4444
.....
Hmmm now,
if only nc was actually our own station server program,
written in C or Python,
we might know what to do with the request,
and what to write back as our reply!
While this part of the project involves sending an HTTP request over a
TCP/IP connection,
and sending an HTTP reply carrying an HTML message back across the
same TCP/IP connection,
we've almost finished it without having written a line of code.
Of course,
we need to replicate some of the work that nc performed
in establishing the server's connection on our chosen port-number (4444),
and that's where our first bit of coding becomes programming-language specific.
Communication between station servers
Station servers communicate with each other using UDP/IP datagrams.
Servers do not establish or maintain connections between each other,
and send datagrams on-demand.
Stations know the ports on which their neighbouring stations are expecting datagrams,
but not the ports of other stations.
Datagrams will be used to transmit both queries and replies
between neighbouring stations.
The contents of each UDP datagram (in its payload) will need to be formatted
so that they can be unambiguously understood by its receiver.
Their format does not need to match that of the HTTP or HTML protocols
(that would be overkill for our requirements).
However, you will be defining a protocol understood by your stations.
Helpful language-specific tutorials on TCP and UDP
- Minimal tutorials on
HTTP - Requests
and
HTTP - Responses,
both from Tutorialspoint.
- For C and C++ developers - A Guide to Network Programming using Internet sockets,
by Brian "Beej" Hall.
- For Python developers -
Transports and
Protocols,
socket - Low-level networking interface,
and
socketserver - A framework for network servers,
all from python.org.
Defining and executing your own transport network
Consider the following excellent diagram of a simple 4-station network:
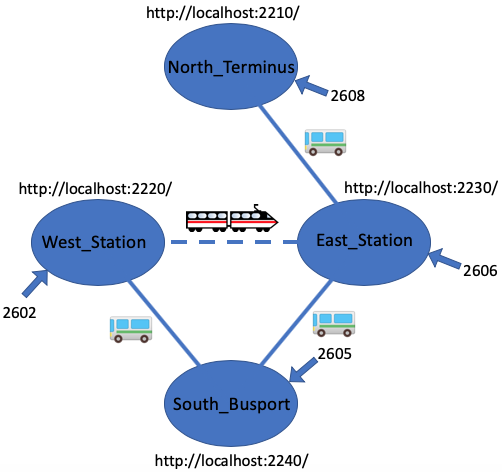
|
- Each station has a distinct name
- Each station is directly connected to others by a (physical) bus or train route
- Each station has a URL enabling a TCP/IP connection from a web-browser
- Each URL specifies the unencrypted HTTP protocol, not encrypted HTTPS
- Each station has a port able to receive UDP/IP datagrams
- Stations only know other station's UDP/IP ports if they're directly connected by a bus or train route
- This example runs on a single computer,
so all URLs refer to the hostname localhost
- This example runs on a single computer,
so all URLs, and TCP and UDP sockets will use distinct ports
|
The above network requires 4 distinct operating system processes to execute,
each written in your choice of two programming languages.
We can invoke all of these processes from the command-line,
or from a shellscript, as below.
Each process receives a small number of command-line arguments,
providing
its station's name,
its unique port for TCP/IP-based communication with a web-browser,
its unique port for UDP/IP-based communication with other stations using datagrams,
the UDP/IP-based port(s) of directly connected (neighbour) stations.
Notice, also,
that all processes have been 'started in the background',
because none needs to remain connected to the invoking keyboard.
shell>
./station North_Terminus 2210 2608 localhost:2606 &
shell>
./station East_Station 2230 2606 localhost:2608 localhost:2602 localhost:2605 &
shell>
./station.py West_Station 2220 2602 localhost:2605 localhost:2606 &
shell>
./station.py South_Busport 2240 2605 localhost:2606 localhost:2602 &
When invoked, each station process first initialises its TCP and UDP ports,
and then reads a comma-separated textfile providing its own timetable information.
While your servers will need to read in and parse the contents of the timetable files,
you can assume that all their contents are correct
(time-formats are correct, departure times precede arrival times, destination station names exist, etc).
For example, the file
tt-North_Terminus
may contain lines of the form:
North_Terminus,-31.8448,115.7963
07:15,12,Stop1,07:54,East_Station
08:15,12,Stop1,08:46,East_Station
....
14:20,12,Stop1,14:50,East_Station
The first line contains the station's name (also forming the filename),
and latitude and longitude
(which you can ignore, though some students wanted to drap a map on their webpages! :-)
The second and subsequent lines each define a single bus connection leaving the station.
The second line can be read as:
"At 7.15am, bus number 12 leaves Stop1, arriving at 7.54am at East_Station".
Note that there is no networking information (protocols or ports)
in the file, and that
North_Terminus
does not know anything about
West_Station
or
South_Busport.
The file
tt-East_Station
will have exactly the same format,
but likely have more timetable entries because it has more direct connections.
East_Station,-31.9442,115.8771
05:15,Line1,PlatformB,06:10,West_Station
05:22,180,StopA,05:51,South_Busport
06:15,Line1,PlatformB,07:18,West_Station
06:16,13,StopC,06:51,North_Terminus
....
Simplifying the building and execution of your transport networks
The following program and shellscripts may help you
to automate the task of constructing (fake) timetables,
and the shell commands to invoke your station servers.
The use of these scripts is not required - they are just suggestions.
In combination, these files generate a shellscript which, when invoked,
will start all station-servers on the same host - localhost.
You can use this approach to develop your project on your own host but,
eventually,
you'll need to modify things to name and invoke commands on remote hosts.
- The C program
buildrandomtimetables.c,
when compiled and executed,
generates a random network of bidirectional links, and creates files holding
its adjacency (connectivity) information and each station's timetables.
Though random, the network is guaranteed to be connected,
and all generated files are in their correct format.
Generate a 6-station network with:
shell> cc -Wall -Werror -o buildrandomtimetables buildrandomtimetables.c
shell> ./buildrandomtimetables 6
- The shellscript
assignports.sh,
takes an adjacency file as input,
and generates another shellscript containing commands to invoke each station server
with available TCP and UDP ports as their arguments.
You will need to edit the generated shellscript to correctly
invoke your servers written in C or Python.
Create a shellscript which starts the station servers:
shell> chmod +x assignports.sh
shell> ./assignports.sh adjacency startstations.sh
- The shellscript
makewebpage.sh
generates an HTML webpage that can be used to contact each server.
The webpage will need to be opened in a web-browser.
Create a webpage to make route queries:
shell> chmod +x makewebpage.sh
shell> ./makewebpage.sh startstations.sh mywebpage.html
 Using the Transperth GTFS dataset Using the Transperth GTFS dataset
Perth's Public Transport Authority (PTA)
provides public access to its scheduled times, stop locations,
and route information from its webpage
www.transperth.wa.gov.au/About/Spatial-Data-Access.
You may download your own copy of the data (about 90MB)
by clicking on the first link "By downloading the data you are agreeing
to the terms of the License..."
The data is released as a collection of inter-related textfiles following the
Google
Transit Feed Specification (GTFS),
which is also used by
many other public transport companies, worldwide.
Finally.
The shellscript
buildtransperthtimetables.sh
(it will probably download when you click on the link),
reads the Transperth files and reduces the information to a set of more manageable timetable files,
suitable for this project.
Read the following points carefully:
-
Do not attempt to use the timetable files produced by this shellscript
unless you have testing your project with a dataset of far fewer, smaller files,
such as the 4-station network, above.
-
Using a downloaded Transperth dataset,
the script runs several minutes -
so grab that cup of coffee.
You only need to run it once, and then keep the timetable files it generates.
-
The script produces a total of 90+ timetable files,
one file for each station.
A station is a physical location where bus and train trips start and stop,
or just pass through.
A station is an 'umbrella' for at least one stop -
for example,
a typical train station may have 2 train platforms,
and 2 bus stops.
A number of stations have just one stop,
Elizabeth Quay Bus Station has 130 stops.
This project only manages stations,
such as physically large bus and train stations and shopping centres,
with each just considered as a single 'big' stop.
Because the generated files do not include every bus stop on every road,
even if visited by many well-known bus routes,
you may not find your familiar routes in the generated files.
-
The Transperth data includes all trips,
scheduled 7 days per week,
with different schedules each day (and accounting for public holidays).
To significantly simplify things
the buildtransperthtimetables.sh script only gathers data for Wednesdays,
and we assume that every day uses the same (Wednesday) schedule.
-
The first line of every timetable file has 3 comma-separated fields -
the station's name, and its latitude and longitude (not required).
Each following line has five comma-separated fields -
the departure time of each bus or train,
the number (or name) of each bus (or train),
a description of the stop from where the bus leaves,
the arrival time at the next (neighbouring) station,
the name of the next (neighbouring) station.
This file format is identical to the
tt-East_Station
example, above.
One stop has just 6 departing trips each day (a 390byte file),
and one stop at Elizabeth Quay has 969 trips (a 78KB file).
-
The Transperth network has 90+ connected stations in the Perth Metropolitan area
(used on Wednesdays).
It should be possible execute the whole network on a single laptop computer
(with station servers written in C or Python),
but that would be a nightmare to debug and manage.
You should approach the project using connected networks of increasing size:
1 station,
2 stations,
5 stations,
10 stations,
20 stations,....
Good luck,
Chris McDonald
|

