|
|
CITS2002 Systems Programming |
 CITS2002
CITS2002 |
CITS2002 schedule |
|||||
Introduction to multi-threaded programmingContemporary computers have the ability to execute multiple operations at the same time - or at least they appear to do so.We know from earlier lectures that operating systems address the concepts of allocating and sharing a single CPU (process scheduling) and RAM (memory management), but we still have competing goals:
In this and the next lecture, we'll casually examine the concept of concurrency - that independent sets of operations can be occurring at the same time. Operating systems allow the user to both manage concurrency and to exploit concurrency to improve performance. The focus here will be more on the user and their programming, than the operating system and its resources.
CITS2002 Systems Programming, Lecture 20, p1, 9th October 2023.
Some definitionsThreads are a programming abstraction designed to allow programmers to control concurrency and asynchrony within a program.In some programming languages, like Java, threads are "first-class citizens" - they are part of the language specification itself. For others languages, like C and C++, threads have not traditionally been part of the language specification, and were implemented as a library of functions linked with, and called by, a program. This changed with C11 which now defines portable threads as part of its standard. The differences between having threads "in the language" and threads "as a library" are subtle and important. For example, a C compiler need not take into account thread control (leaving that to the programmer), while a Java compiler must. Analogously, we see that C enables fine-grain control of memory mangement, while Java strictly defines it as part of its standard. In the library case, it is possible to choose from different thread libraries to provide different semantics. In contrast, (all conforming) Java and C11 programs are required to support their single thread model and API. What is a thread?We'll informally define threads within a program to include three things:
This definition corresponds roughly to the C language model of sequential execution and variable scoping. Operating systems are still significantly written in C and, thus, thread libraries for C are easiest to understand and implement when they conform to a familiar model. And why?Threads provide two important opportunities:
CITS2002 Systems Programming, Lecture 20, p2, 9th October 2023.
The motivation for threadsThreads are very useful in modern programming whenever a process has multiple 'tasks' to perform independently of the others. This is particularly true when one of the tasks may block, but allows the other tasks can proceed without blocking.
And the benefitsThere are four core benefits to multi-threading:
CITS2002 Systems Programming, Lecture 20, p3, 9th October 2023.
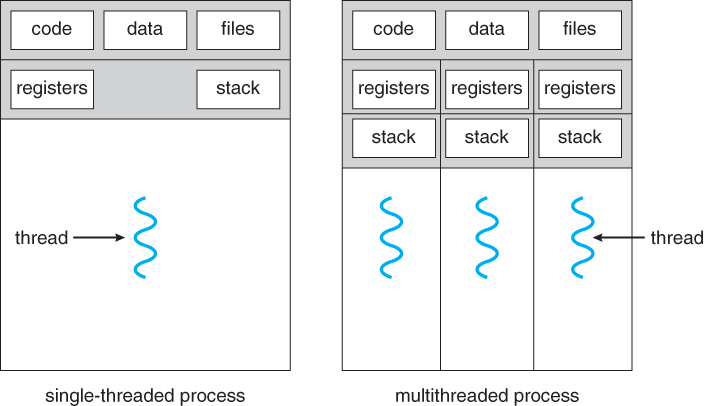
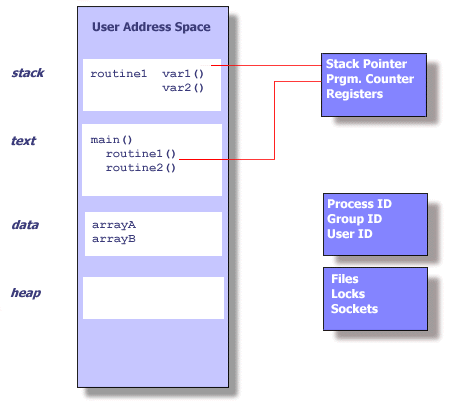
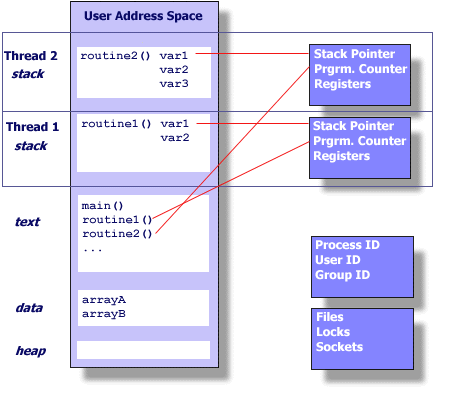
Differences between processes and threadsTo date we've seen that a compiled C program becomes a process when passed to the execve() system call. Like our informal definition of threads, a C program also defines a sequence of instructions, local variables, and global variables, so what's the difference?The primary difference is the degree of independence between processes, and between threads.
CITS2002 Systems Programming, Lecture 20, p4, 9th October 2023.
Characteristics of processes and threads
CITS2002 Systems Programming, Lecture 20, p5, 9th October 2023.
POSIX threads and the pthreads libraryAs with many early concepts in computing, historically, different hardware vendors implemented their own proprietary versions of threads. These implementations differed substantially from each other making it difficult for programmers to develop portable threaded applications.In order to take full advantage of the capabilities provided by threads, a standardized programming interface was required.

For UNIX-based systems, this interface has been specified by the IEEE POSIX 1003.1c standard (1995). Implementations conforming to this standard are referred to as POSIX threads, or pthreads. Most operating system vendors now offer pthreads in addition to their proprietary APIs.
pthreads are defined as a set of C language datatypes and
function calls,
declared with a <pthread.h> header file and
defined in a thread library
Some useful references:
CITS2002 Systems Programming, Lecture 20, p6, 9th October 2023.
Creating and terminating POSIX threadsInitially, each process comprises a single, default thread. All other threads must be explicitly created at run-time.The function pthread_create() creates a new thread and marks it as executable. pthread_create() can be called any number of times from anywhere within your code (including from within running threads). pthread_create() accepts the arguments:
CITS2002 Systems Programming, Lecture 20, p7, 9th October 2023.
Passing initial arguments to POSIX threadsOnly a single argument may be passed to a new thread but, as that argument is a pointer, we may pass reference to any amount of data pointed to by that pointer.In our previous example, we simply passed the address of a single integer. In this example we pass the address of a structure, and each new thread receives its own instance of a structure:
CITS2002 Systems Programming, Lecture 20, p8, 9th October 2023.
Joining and detaching POSIX threads"joining" is the simplest way to accomplish synchronization between threads. The pthread_join() function blocks the calling thread, perhaps just main(), until the specified threadID thread terminates.As with traditional Linux processes and the wait() system-call, we are waiting for the requested thread to terminate, and are able to receive termination information when it terminates.
When a thread is created, one of its attributes defines whether it is joinable or detached. Only joinable threads can be joined(!). If a thread is created as detached, it can never be joined. If we know in advance that a thread will never need to join with another thread, it is usually created in the detached state. Some system resources may be able to be freed.
CITS2002 Systems Programming, Lecture 20, p9, 9th October 2023.
Stack management of POSIX threadsThe POSIX thread standard does not define the size of each thread's stack. Different operating systems will determine the default size (execute ulimit -a).A process's stack is used to receive parameters, to provide space for local variables, and store stack frames when other functions are called. Choosing the appropriate stack size for each thread can be very important - too small and code execution will accidentally overwrite another thread's storage, too large and we'll possibly be wasting storage. If we know ahead of time that a particular thread requires, say, a large per-thread stack - perhaps because it has many or large local variables, or will need to make many 'deep' function calls - then we should not rely on the default stack size, but should specify the required size at time of thread creation.
It is notable that we have this fine-grained control when creating individual functions as threads, but not when fork()ing new processes.
CITS2002 Systems Programming, Lecture 20, p10, 9th October 2023.
|