The standard command-line arguments
In all of our C programs to date
we've seen the use of,
but not fully explained,
command-line arguments.
We've noticed that the main() function
receives command-line arguments from its calling environment
(usually the operating system):
#include <stdio.h>
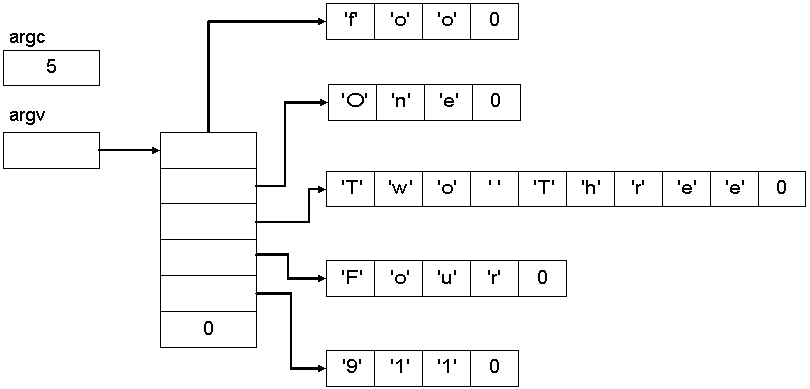
int main(int argc, char *argv[])
{
printf("program's name: %s\n", argv[0]);
for(int a=0 ; a < argc ; ++a) {
printf("%i: %s\n", a, argv[a] );
}
return 0;
}
|
|
|
We know:
- that argc provides the count of the number of arguments, and
- that all programs receive at least one argument (the program's name).
CITS2002 Systems Programming, Lecture 18, p1, 2nd October 2023.
But what is argv?
If we read argv's definition, from right to left, it's
"an array of pointers to characters"
Or, try cdecl.org
While we typically associate argv with strings,
we remember that C doesn't innately support strings.
It's only by convention or assumption that we may assume that each
value of argv[i] is a pointer to something that we'll treat as a
string.
In the previous example,
we print "from" the pointer.
Alternatively, we can print every character in the arguments:
#include <stdio.h>
int main(int argc, char *argv[])
{
for(int a=0 ; a < argc ; ++a) {
printf("%i: ", a);
for(int c=0 ; argv[a][c] != '\0' ; ++c) {
printf("%c", argv[a][c] );
}
printf("\n");
}
return 0;
}
|
|
|
The operating system actually makes argv much more usable, too:
- each argument is guaranteed to be terminated by a null-byte (because
they are strings), and
- the argv array is guaranteed to be terminated by a
NULL pointer.
CITS2002 Systems Programming, Lecture 18, p2, 2nd October 2023.
Parsing command-line arguments
By convention,
most applications support command-line arguments
(commencing with a significant character)
that appear between a program's name and the "true" arguments.
For programs on Unix-derived systems (such as Apple's macOS and Linux),
these are termed command switches,
and their introductory character is a hyphen, or minus.
Keep in mind, too, that many utilities appear to accept their
command switches in (almost) any order.
For the common ls program to list files,
each of these is equivalent:
- ls -l -t -r files
- ls -lt -r files
- ls -ltr files
- ls -rtl files
Of note,
neither the operating system nor the shell
know the switches of each program,
so it's up to every program to detect them, and report any problems.
CITS2002 Systems Programming, Lecture 18, p3, 2nd October 2023.
Parsing command-line arguments, continued
Consider the following program,
that accepts an optional command switch, -d,
and then zero or more filenames:
#include <stdio.h>
#include <stdlib.h>
#include <stdbool.h>
char *progname;
bool dflag = false;
int main(int argc, char *argv[])
{
progname = argv[0];
--argc; ++argv;
while(argc > 0 && (*argv)[0] == '-') { // or argv[0][0]
if((*argv)[1] == 'd') // or argv[0][1]
dflag = !dflag;
else
argc = 0;
--argc; ++argv;
}
if(argc < 0) {
fprintf(stderr, "Usage : %s [-d] [filename]\n", progname);
exit(EXIT_FAILURE);
}
if(argc > 0) {
while(argc > 0) {
process_file(*argv); // provide filename to function
--argc; ++argv;
}
}
else {
process_file(NULL); // no filename, use stdin or stdout?
}
return 0;
}
|
CITS2002 Systems Programming, Lecture 18, p4, 2nd October 2023.
Parsing command-line arguments with getopt
As programs become more complicated,
they often accept many command switches to define and constrain
their execution (something casually termed
creeping featurism [1]).
In addition, command switches do not just indicate, or toggle, a Boolean
attribute to the program,
but often provide additional
string values and numbers to further control the program.
The correct parsing of command switches can quickly become complicated!
To simplify the task of processing command switches in our programs,
we'll use the function getopt().
getopt() is not a function in the Standard C library but,
like the function strdup(),
it is widely available and used.
In fact,
getopt() conforms to a different standard -
an POSIX standard [2],
which provides functions enabling operating system portability.
[1] UNIX Style, or cat -v Considered Harmful
[2] The
IEEE Std 1003.1 (POSIX.1-2017)
CITS2002 Systems Programming, Lecture 18, p5, 2nd October 2023.
Parsing command-line arguments with getopt, continued
Let's repeat the previous example using getopt:
#include <stdio.h>
#include <stdbool.h>
#include <unistd.h>
#include <getopt.h>
#define OPTLIST "d"
int main(int argc, char *argv[])
{
int opt;
.....
opterr = 0;
while((opt = getopt(argc, argv, OPTLIST)) != -1) {
if(opt == 'd')
dflag = !dflag;
else
argc = -1;
}
if(argc < 0) {
fprintf(stderr, "Usage: %s [-d] [filename]\n", progname);
exit(EXIT_FAILURE);
}
while(optind < argc) {
process( argv[optind] );
++optind;
}
.....
return 0;
}
|
CITS2002 Systems Programming, Lecture 18, p6, 2nd October 2023.
Parsing command-line arguments with getopt, continued
Let's repeat the previous example,
but now support an additional command switch that provides a number as
well.
The getopt function is informed,
through the OPTLIST character string,
that an argument is expected after the new -n switch.
#include <stdio.h>
#include <stdbool.h>
#include <stdlib.h>
#include <string.h>
#include <unistd.h>
#include <getopt.h>
#define OPTLIST "df:n:"
int main(int argc, char *argv[])
{
int opt;
bool dflag = false;
char *filenm = NULL;
int value = DEFAULT_VALUE;
opterr = 0;
while((opt = getopt(argc, argv, OPTLIST)) != -1) {
// ACCEPT A BOOLEAN ARGUMENT
if(opt == 'd') {
dflag = !dflag;
}
// ACCEPT A STRING ARGUMENT
else if(opt == 'f') {
filenm = strdup(optarg);
}
// ACCEPT A INTEGER ARGUMENT
else if(opt == 'n') {
value = atoi(optarg);
}
// OOPS - AN UNKNOWN ARGUMENT
else {
argc = -1;
}
}
if(argc <= 0) { // display program's usage/help
usage(1);
}
argc -= optind;
argv += optind;
.....
return 0;
}
|
getopt sets the global pointer variable optarg
to point to the actual value provided after -n -
regardless of whether any spaces appear between the switch and the value.
CITS2002 Systems Programming, Lecture 18, p7, 2nd October 2023.
Inter-process communication
When writing programs, we don't write all of the code ourselves.
Wherever possible,
we employ standard, well-tested, functions - both from programming
language standard libraries and from 3rd-party developers.
Similarly,
our running programs - processes -
should not attempt to perform all of the work themselves,
if there is a standard, well-tested resource that can perform some of the work.
Processes do not, should not, work in isolation,
and should communicate with other processes if useful to do so.
Contemporary operating systems provide a number inter-process communication (IPC) mechanisms.
Examples include:
- asynchronous signals
- unidrectional anonymous pipes (in-memory FIFO buffers)
- named pipes (on-disk FIFO files)
- in-memory message-queues
- shared memory blocks, permitting processes to 'share' an array or other data-structure
- sockets, to communicate with local- or remote processes across a network
(CITS3002 Computer Networks)
CITS2002 Systems Programming, Lecture 18, p8, 2nd October 2023.
Inter-process communication - filters
This is the Unix philosophy: write programs that do one thing and do
it well. Write programs to work together. Write programs that handle
text streams, because that is a universal interface.
Douglas McIlroy, Bell System Technical Journal, 1978
One of the most successful ideas introduced in early Unix systems was the interprocess
communication mechanism termed a pipe.
Pipes enable shells (or other programs) to connect the output of one
program to the input of another, and for arbitrary sequences of pipes - a pipeline -
to filter a data-stream with a number of transformations.
A great pipeline example, providing a rudimentary spell-checker:
prompt>tr -cs 'A-Za-z' '\n' < inputfilename | sort -u | comm -23 - /usr/share/dict/words
Programs typically used in pipelines are termed filters, and they
work in combination because of their simple communication schemes which do
not add 'unexpected detail' to their output, so that programs reading that
output as their input only have the expected data-stream to process.
Unix-based systems provide a huge number of utility programs that filter their standard-input,
writing their 'results' to stdout-output:
comm,
cut,
grep,
gzip,
head,
join,
merge,
paste,
sort,
tail,
tee,
tr,
uniq,
wc,
zcat
It's for this reason that programs don't produce verbose natural-language
descriptions of their output, no headings for tables of data, unless a
specific command-line option requests it. Just the facts.
CITS2002 Systems Programming, Lecture 18, p9, 2nd October 2023.
Inter-process communication using pipes in C
Contemporary systems provide a system call,
imaginatively named pipe(),
to create a unidirectional communication buffer.
- Within the operating system kernel,
a pipe is a vector of memory, typically 4096 bytes long
- From within a C program,
a pipe is represented as an array of two integer file-descriptors.
Writing data to array[0] adds the data to the pipe,
and reading from array[1] removes that data.
#include <unistd.h>
int thepipe[2];
char data[1024];
int datasize, nbytes;
if(pipe(thepipe) != 0) {
perror("cannot create pipe");
exit(EXIT_FAILURE);
}
datasize = ...
nbytes = write( thepipe[0], data, datasize); // write to the pipe
nbytes = read( thepipe[1], data, sizeof(data)); // read from the pipe
|
Pipes have a finite size, typically 4096 bytes,
and their typical use affects the scheduling of processes connected by the same pipe:
- A newly created pipe is empty.
- Data written to the writing end is added to the pipe.
- If a process tries to write more data than will fit in the pipe,
that writing process is blocked until space becomes available.
- Data read from the reading end is removed from the pipe.
- If a process tries to read more data than is held in the pipe
(including if the pipe is empty)
then that reading process is blocked until data becomes available.
- A pair of processes writing and reading using the same pipe,
'cause' those processes to (roughly) alternate their execution.
CITS2002 Systems Programming, Lecture 18, p10, 2nd October 2023.
Inter-process communication using pipes in C, continued
While the previous code will work
(a single process can write-and-read with itself!),
the true power of pipes obviously comes when two processes communicate using the same pipe.
- But, if a pipe is an array of two integers, how do two processes access that same array?
The solution requires that processes sharing a pipe must be 'related'.
In the following example,
a (parent) process creates a pipe,
forks a child process,
and both processes now have access to the same pair of file descriptors:
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>
void communicate(void)
{
int> thepipe[2]
char data[1024];
int datasize, nbytes;
if(pipe(thepipe) != 0) {
perror("cannot create pipe");
exit(EXIT_FAILURE);
}
// fork()ing THE PROCESS WILL DUPLICATE ITS DATA, INCLUDING THE pipe'S TWO FILE-DESCRIPTORS
switch ( fork() ) {
case -1 :
printf("fork() failed\n"); // process creation failed
exit(EXIT_FAILURE);
break;
case 0: // new child process
close( thepipe[0] ); // child will never write to pipe
nbytes = read( thepipe[1], data, sizeof(data)); // read from the pipe
....
close( thepipe[1] );
exit(EXIT_SUCCESS);
break;
default: // original parent process
close( thepipe[1] ); // parent will never read from pipe
datasize = ...
nbytes = write( thepipe[0], data, datasize); // write to the pipe
....
close( thepipe[0] );
break;
}
}
|
CITS2002 Systems Programming, Lecture 18, p11, 2nd October 2023.
Duplicating file-descriptors using dup2()
Of course it's very unusual for a child process to keep running the 'same code'
as its parent process.
More typically,
the child process will call execl() to commence the execution of another program.
Even though a new program commences,
the process's open file-descriptors remain open.
Moreover,
if the new program (such as sort) is a filter
expecting to receive its input via its standard-input stream
(file descriptor 0),
then we must perform to 'plumbing'
with the dup2() system-call
to arrange our descriptors:
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>
void communicate(void)
{
....
switch ( fork() ) {
....
// CHILD PROCESS RUNS sort, READING ITS stdin FROM THE PIPE
case 0 : // new child process
close( thepipe[1] ); // child will never write to pipe
dup2( thepipe[0], 0); // duplicate/clone the reading end's descriptor and stdin
close( thepipe[0] ); // close the reading end's descriptor
// child may now read from its stdin (fd=0)
execl("/usr/bin/sort", "sort", NULL); // execute a new (filter) program
perror("/usr/bin/sort");
exit(EXIT_FAILURE);
break;
default : // parent process
close( thepipe[0] ); // parent will never read from pipe
dup2( thepipe[1], 1); // duplicate/clone the writing end's descriptor and stdout
close( thepipe[1] ); // close the writing end's descriptor
// parent may now write to its stdout (fd=1)
....
break;
}
}
|
CITS2002 Systems Programming, Lecture 18, p12, 2nd October 2023.
|

 CITS2002
CITS2002