|
|
CITS3002 Computer Networks |
 CITS3002
CITS3002 |
help3002 |
CITS3002 schedule |
|||||
CITS3002 Computer Networks, Lecture 5, The Network Layer, p1, 25th March 2024.
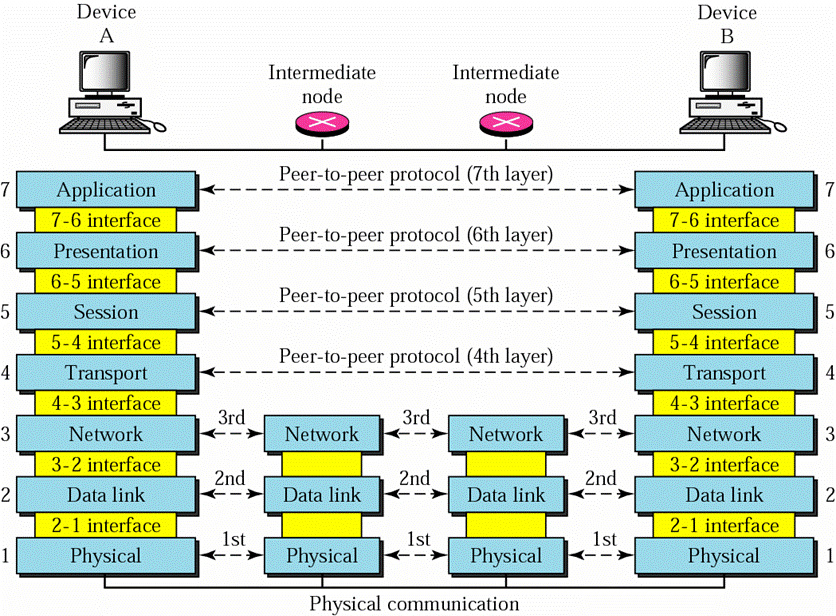
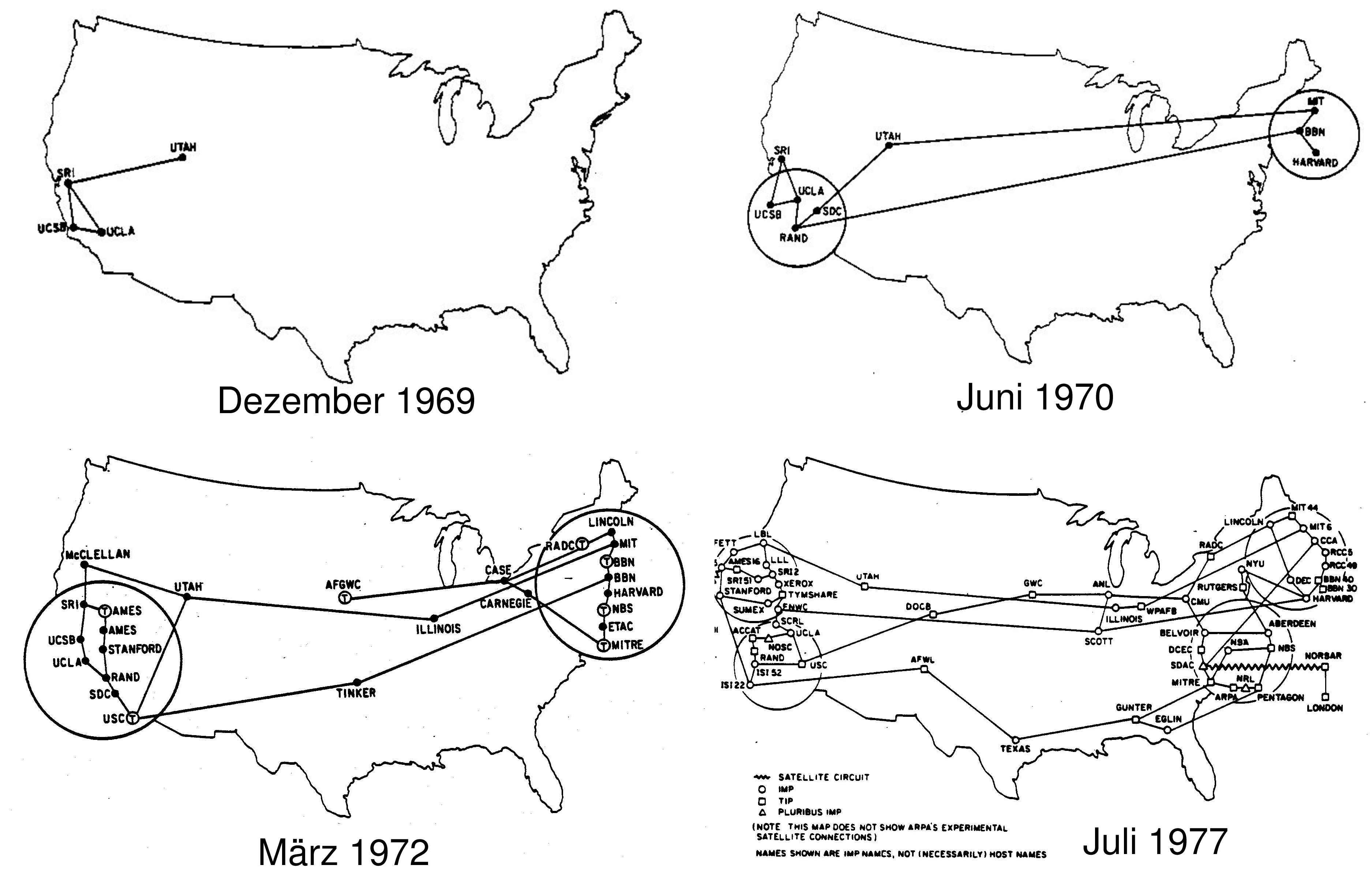
The Relationship Between Hosts and the Subnet
To place it in perspective,
the Network Layer software runs in dedicated devices termed
routers -
early editions of Tanenbaum introduced the term
IMPs (Intermediate Message Processors),
and the Transport Layer (coming soon) runs in the hosts.
 Implications for Data Link Layer softwareExcept in the trivial 2-node case, some nodes will now have more than one physical link to manage. When the Network Layer presents a packet (data or a control message) to the Data Link Layer, it must now indicate which physical link is involved. Each link must have its own Data Link protocol - its own buffers for the sender's and receiver's windows and state variables such as ackexpected, nextframetosend, etc.
CITS3002 Computer Networks, Lecture 5, The Network Layer, p2, 25th March 2024.
CITS3002 Computer Networks, Lecture 5, The Network Layer, p3, 25th March 2024.
CITS3002 Computer Networks, Lecture 5, The Network Layer, p4, 25th March 2024.
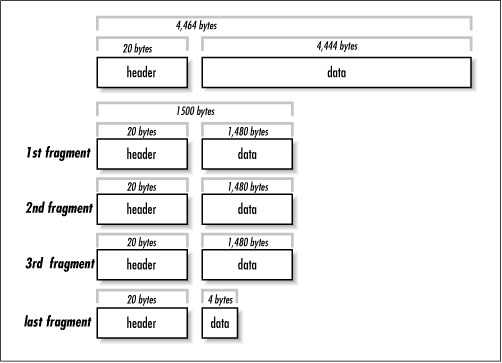
Network Layer Header ManagementThe Network Layer data unit, the packet, carries a Network Layer header which must serve many purposes. The NL header is created in the source node, examined (and possibly modified) in intermediate nodes, and removed (stripped off) in the destination node. The Network Layer headers typically contain (note that not all NL protocols will require or implement all of these fields or responsibilities):
Finally, the data portion (the payload) of the packet includes the 'user-data', control commands or network-wide statistics.
CITS3002 Computer Networks, Lecture 5, The Network Layer, p5, 25th March 2024.
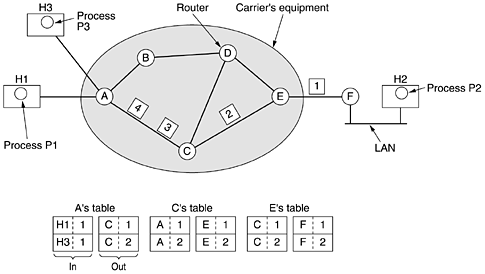
The Path of Frames and PacketsWhereas the Data Link Layer must acknowledge each frame once it successfully traverses a link, the Network Layer acknowledges each packet as it arrives at its destination.
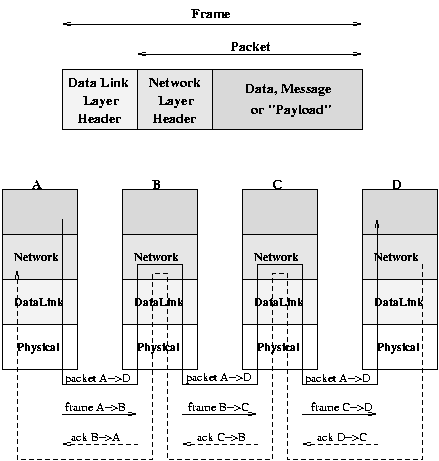 Note the significant 'explosion' in the number of frames required to deliver each packet.
CITS3002 Computer Networks, Lecture 5, The Network Layer, p6, 25th March 2024.
The Two Contending Network Layer SchemesSo, how to design and implement the complex responsibilities of the Network Layer?One community (the telecommunications companies) believe that all data should be transmitted reliably by the Network Layer.
CITS3002 Computer Networks, Lecture 5, The Network Layer, p7, 25th March 2024.
The Two Contending Network Layer Schemes, continuedIn contrast, the other group is the Internet community, who base their opinions on 40+ years' experience with a practical, working implementation. They believe the subnet's job is to transmit bits, and it is known to be unreliable.
CITS3002 Computer Networks, Lecture 5, The Network Layer, p8, 25th March 2024.
Network Layer Routing AlgorithmsThe routing algorithms are the part of the Network layer software that decides on which outgoing line an incoming packet should go.
Desirable properties for the routing algorithms are similar to those for the whole Network layer :
correctness, simplicity, robustness, stability, fairness and optimality.
In particular, robustness often distinguishes between the two main classes of routing algorithms - adaptive and non-adaptive. Robustness is significant for two reasons :
The better a routing algorithm can cope with changes in topology, the more robust it is.
CITS3002 Computer Networks, Lecture 5, The Network Layer, p9, 25th March 2024.
The Two Classes of Routing Algorithm
Question: How do we know when a host, router or line has failed?
CITS3002 Computer Networks, Lecture 5, The Network Layer, p10, 25th March 2024.
A naive non-adaptive routing algorithm - FloodingInitially, every 'incoming' packet is retransmitted on every link:
Advantage : flooding gives the shortest packet delay (the algorithm chooses the shortest path because it chooses all paths!) and is robust to machine failures.
CITS3002 Computer Networks, Lecture 5, The Network Layer, p11, 25th March 2024.
Improved Flooding AlgorithmsDisadvantage : flooding really does flood the network with packets! When do they stop? Partial Solutions :
Examples: Three implementations of flooding are provided in
.../resources/flooding.zip.
CITS3002 Computer Networks, Lecture 5, The Network Layer, p12, 25th March 2024.
Adaptive Routing - Distance Vector RoutingDistance vector routing algorithms maintain a table in each router of the best known distance to each destination, and the preferred link to that destination. Distance vector routing is known by several names, all descending from graph algorithms (Bellman-Ford 1957, and Ford-Fulkerson 1962). Distance vector routing was used in the wider ARPANET until 1979, and was known in the early Internet as RIP (Routing Information Protocol).
Consider the following:
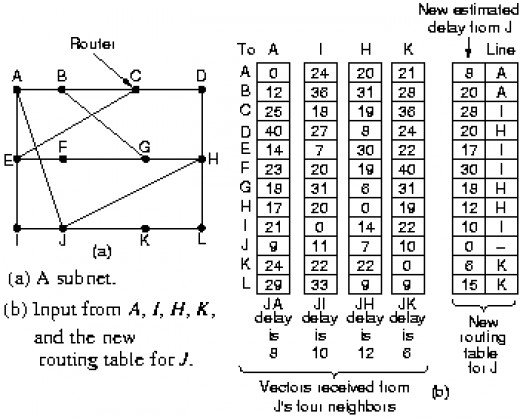 Router J has recently received update tables from its neighbours (A,I,H,K) and needs to update its table. Note that J does not use its previous table in the calculations.
CITS3002 Computer Networks, Lecture 5, The Network Layer, p13, 25th March 2024.
The Count-To-Infinity ProblemThere is a simple, though serious, problem with the distance vector routing algorithms that requires them all to be modified in networks where the reliability is uncertain (links and routers may crash). Consider the following [Tan 5/e, Fig 5-11].
 When router A returns, each other router eventually hears of its return, one router at a time - good news travels fast. However, consider the dual problem in (b). Router A is initially up. All other routers know the distance to A. Now, router A crashes - router B first senses that A is now an infinite distance away. However, B is excited to learn that router C is a distance of 2 to A, and so B chooses to now send traffic to A via C (a distance of 3). At the next exchange, C notices that its 2 neighbours each have a path to A of length 3. C now records its path to A, via B, with a distance of 4. At the next exchange, B has direct path to A (of infinite distance), or one via C with a distance of 4. B now records its path to A is via C with a distance of 5.....
CITS3002 Computer Networks, Lecture 5, The Network Layer, p14, 25th March 2024.
Adaptive Routing - Link State RoutingInitially, all ARPANET links were the same speed (56Kbps), and so the routing metric was just hops. As diversity increased (some links became 230Kbps or 1.544Mbps) other metrics were required. In addition, the growing size of the network exposed the slow convergence of distance vector routing. A simple example:
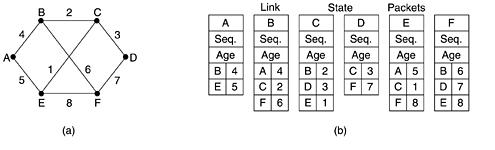 Routers using link state routing periodically undertake 5 (easy to understand) steps:
CITS3002 Computer Networks, Lecture 5, The Network Layer, p15, 25th March 2024.
Congestion and Flow-Control in the Network LayerAn additional problem to be addressed by the Network Layer occurs if too many packets are 'dumped' into some part of the subnet - network performance will degrade sharply. Worse still, when performance degrades, timeouts and re-transmission of packets will increase. Also, if all available buffer space in each router is exhausted, then incoming packets will be discarded (what??!!), causing further re-transmissions. Congestion is both a problem that a node's Network Layer must avoid (not introduce), and must address (if other nodes' Network Layers cause it).
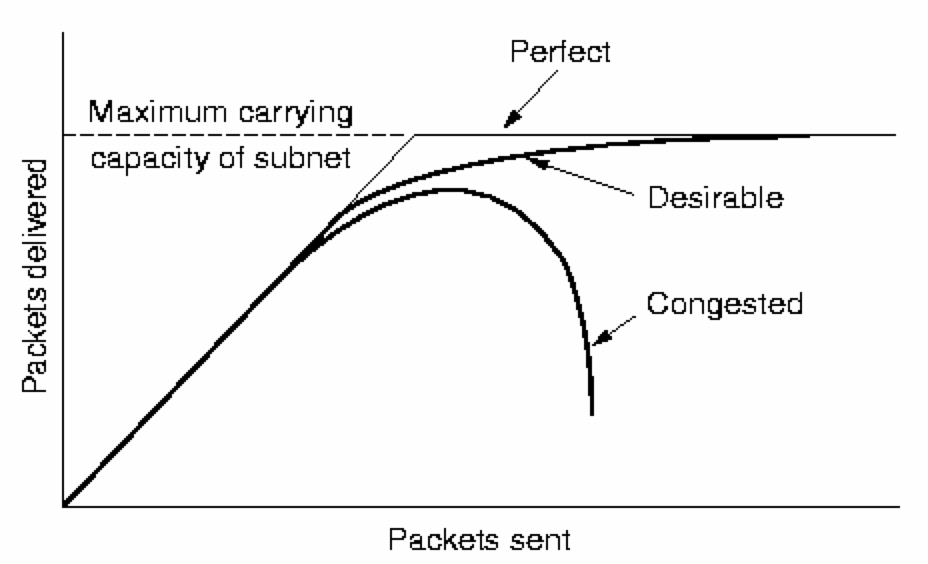
The sender must not swamp the receiver, and typically involves direct feedback from the receiver to the sender to 'slow down'.
CITS3002 Computer Networks, Lecture 5, The Network Layer, p16, 25th March 2024.
Congestion and Flow-Control, continuedBoth congestion and flow-control have the same aim - to reduce the offered traffic entering the network when the load is already high. Congestion will be detected through a number of local and global metrics -
The distinction often depends on the philosophy - virtual circuits or datagrams. Open loop control attempts to prevent congestion in the first place (good design), rather than correcting it. Virtual circuit systems will perform open loop control by preallocating buffer space for each virtual circuit (VC).
Closed loop control maintains a feedback loop of three stages -
CITS3002 Computer Networks, Lecture 5, The Network Layer, p17, 25th March 2024.
End-to-end Flow ControlIt is reasonable to expect conditions, or the quality of service, in the Network Layer to change frequently. For this reason, the sender typically requests the allocation of buffer space and 'time' in the intermediate nodes and the receiver.
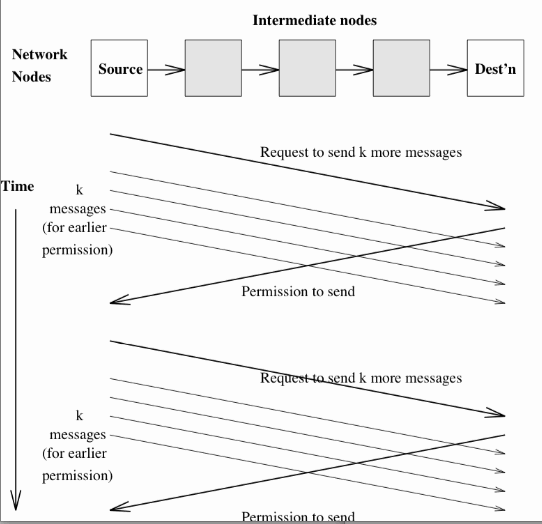 Packets are then sent in groups while the known conditions prevail.
CITS3002 Computer Networks, Lecture 5, The Network Layer, p18, 25th March 2024.
Load SheddingThe term load shedding is borrowed from electrical power supplies - if not all demand can be met, some section is deliberately disadvantaged. The approach is to discard packets when they cannot all be managed. If there is inadequate router memory (on queues and/or in buffers) then discard some incoming packets.
The Network Layer now introduces an unreliable service!
Load shedding must be performed under many constraints:
A number of reasonable strategies exist for discarding packets:
CITS3002 Computer Networks, Lecture 5, The Network Layer, p19, 25th March 2024.
Traffic Shaping - Leaky Bucket AlgorithmConsider a leaking bucket with a small hole at the bottom. Water can only leak from the bucket at a fixed rate. Water that cannot fit in the bucket will overflow the bucket and be discarded. Turner's (1996) leaky bucket algorithm enables a fixed amount of data to leave a host (enter a subnet) per unit time. It provides a single server queueing model with a constant service time.
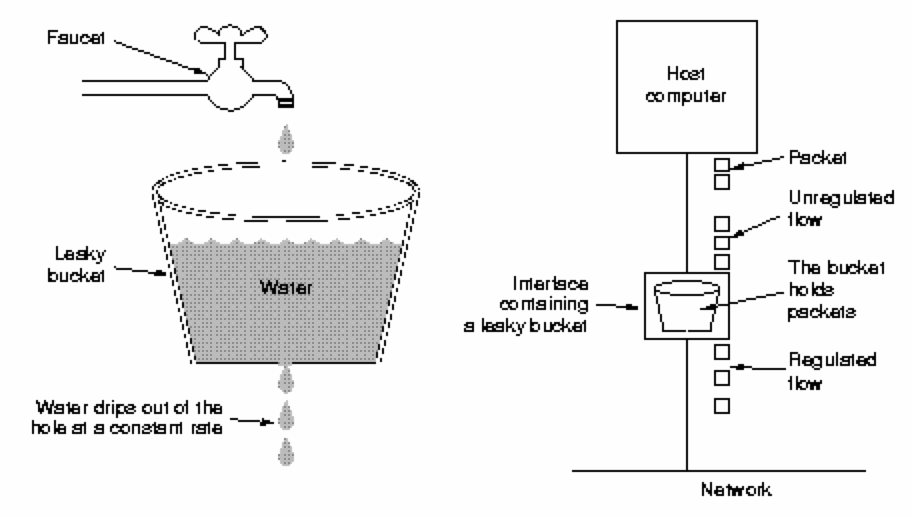 If packets are of fixed sizes (such as 53-byte Asynchronous Transfer Mode cells), one packet may be transmitted per unit time. If packets are of variable size, a fixed number of bytes (perhaps multiple packets) may be admitted. The leaky bucket algorithm enables an application to generate traffic which is admitted to the network at a steady rate, thus not saturating the network.
CITS3002 Computer Networks, Lecture 5, The Network Layer, p20, 25th March 2024.
Traffic Shaping - Token Bucket AlgorithmThe leaky bucket algorithm enforces a strict maximum traffic generation. It is often better to permit short bursts, but thereafter to constrain the traffic to some maximum. The token bucket algorithm provides a bucket of permit tokens - before any packet may be transmitted, a token must be consumed. Tokens 'drip' into the bucket at a fixed rate; if the bucket overflows with tokens they are simply discarded (the host does not have enough traffic to transmit).
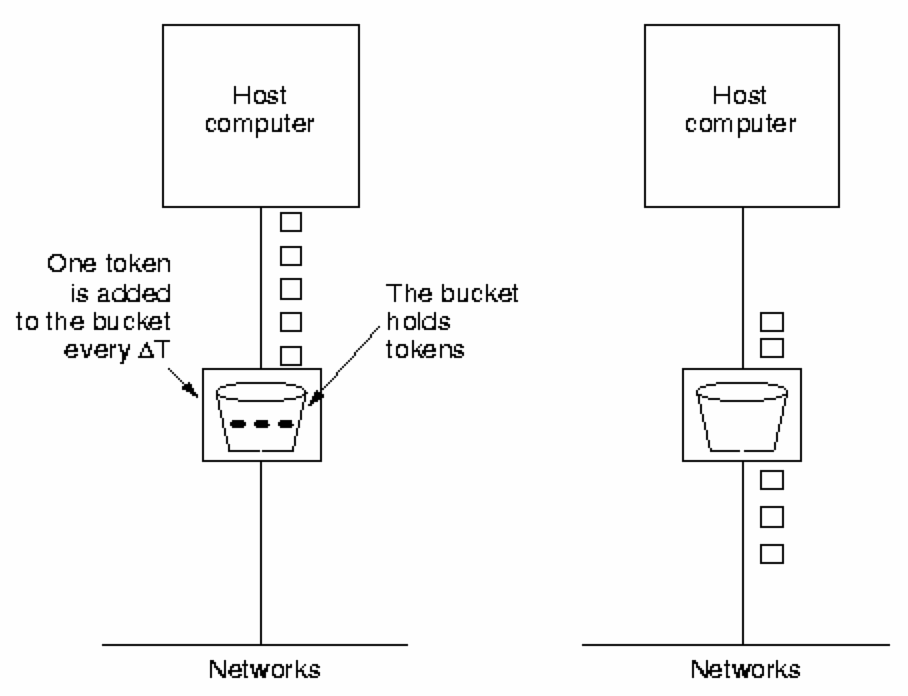 Packets are placed in an 'infinite' queue. Packets may enter the subnet whenever a token is available, else they must wait. The token bucket algorithm enables an application to generate and transmit 'bursty' traffic (high volume, for a short period). It avoids saturating the network by only permitting a burst of traffic to continue for a limited time (until the tokens run out).
CITS3002 Computer Networks, Lecture 5, The Network Layer, p21, 25th March 2024.
|