|
|
Workshop 8: Building a hashtable data structure
|
A self-referential data structure consists of a user-defined
datatype (such as a C11 structure)
which includes one or more pointers to instances of the same datatype.
Examples include lists, queues, and binary trees,
with each used for different purposes and exhibiting different performance.
Unlike more modern programming languages,
C does not provide these as standard datatypes.
One data structure that has grown in prominence in newer programming
languages is the hashtable (or hashmap, or dictionary).
They are similar to arrays,
in that we use an index to insert or find a required item.
However, unlike the standard arrays in C,
where the index must be a non-negative integer,
a hashtable's index may be another type,
such as a string.
For this workshop we'll combine our understanding of
arrays,
structures,
and lists
to construct a hashtable.
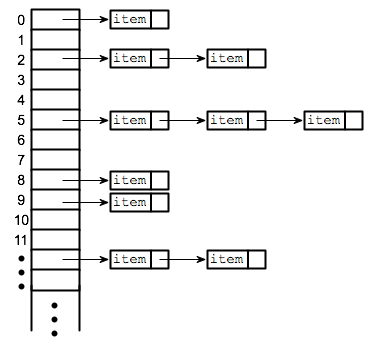
Consider the figure at right.
In English,
we have an array of pointers,
each of which points to a list.
Each list consists of linked structures,
with each structure containing a data item (we'll store strings),
and a pointer to another similar structure.
The end of each list is indicated by a NULL-pointer in the 'last' structure.
|
|
Approach the problem in this sequence:
- Firstly,
design a C11 user-defined list datatype.
Each element of the list will store a data item (a string),
and a pointer to another (the next) list element.
- Next,
write a function to add a string to a list
(storing each string only once),
and a Boolean function to find a string in a list.
- Next,
define a large array of, say, 1000 lists.
Name this array hashtable.
- Now,
here's the 'magic' of the hashtable data structure.
We'll use a hash function,
which accepts a single string as its parameter,
and returns an integer result.
We'll use the integer result as an index into our array of lists -
thus, the string is used to determine in which list the string should be
stored (and later found).
Here is a
typical hash function
(there are many, many others)
which accepts a string parameter,
and returns an unsigned 32-bit integer as its result.
We can determine the required array index by calling
hash_string() and then 'limiting'
its result so that it doesn't exceed our array size:
int index = hash_string( "workshop" ) % 1000; // should be 317
- Now,
write functions add_string_to_hashtable()
and find_string_in_hashtable()
to test your understanding.
-
 Why did we do this?
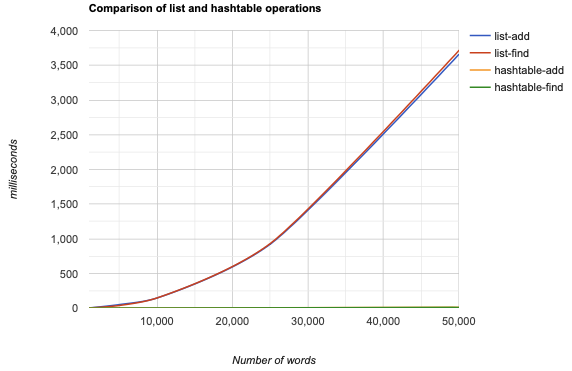
The performance of a hashtable can be dramatically better than other
data structures,
such as arrays, lists and binary trees.
Why did we do this?
The performance of a hashtable can be dramatically better than other
data structures,
such as arrays, lists and binary trees.
For a collection of several thousand (a million?) random strings use the
milliseconds.c
function
to measure how long in takes to insert,
and to then find,
the same set of strings with both an array and your new hashtable.
|
|
Before the workshop session you're strongly encouraged to think how
you would do it.
You are not expected to have developed and tested a perfect solution before
the workshop,
but you should at least scratch out your approach on paper.
Some people get seriously excited about efficient hashtables!
I Wrote The Fastest Hashtable
|

